{kind=link}
There are multiple ways of running a hived node. In this post we use docker compose for an easier setup. By default everything will be contained in one directory for easier management.
Recently @gtg also published a good post. You might want to check that out. It is a good post specially for the exchanges:
Hive Node Setup for the Smart, the Dumb, and the Lazy.
Requirements
- Ubuntu 22
- Storage:
- 1TB: for running a proper node with all the blockchain data
-
- recommended for seed nodes and witness nodes
- 50GB: for pruned node
-
- This node won't keep any blockchain data
-
- e.g. use case would be having trusted source of state data like balances
-
- To run \"pruned\" node you must add
block-log-split = 0(orblock-log-split = 1for one million blocks in storage) in config.ini
- To run \"pruned\" node you must add
- RAM: 4-64GB
- You can get away with less ram by putting shared_memory on disk
- I would recommend at least 8GB of RAM - Feel free to experiment
- Otherwise you need at least 24GB of RAM dedicated for SHM (shared_memory)
- 32GB "should" be fine in this case - have not tested
- With more plugins your SHM might grow and you might need more RAM
- SHM on disk is totally fine (NVME/SSD)
Docker
Docker installation is simple:
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
Optional security step:
You might want to run hived and docker under a non-root user which is recommended.
# Create a non-root user - I name it "myuser"
# and allow it to run docker
sudo useradd -m -G docker myuser
# login as myuser
su - myuser
While on the security topic, you might want to disable the password login on your server and use ssh keys and also install fail2ban for additional security. You can do that after setting up hived with the help of internet.
Hived
git clone https://gitlab.com/mahdiyari/hived_docker
cd hived_docker
cp .env.example .env
Now edit .env file accordingly. You set the hived version and the hived arguments there.
nano .env
P2P sync
For a p2p sync set ARGUMENTS="" in the .env file (which is done by default).
# Start hived in the background
docker compose up -d
Replay
The p2p sync should be fast enough for most people and I would recommend just doing that but if you already have a block_log you can try replaying.
The newer hived (not released yet - v1.27.7) by default will use splitted block logs instead of the legacy single block_log file. So even if you put one block_log, it will split it first and you should pay attention to your storage space in this case as 1TB might not be enough. To keep using the single block_log, you have to edit the config.ini before replaying.
By default the config.ini will be in the following location:
nano datadir/config.ini
Add block-log-split = -1 to keep block_log a single file.
You need ARGUMENTS="--replay" in the .env file. Then:
docker compose up -d
I recommend the P2P sync if you already don't have a block_log as the download speed of the block_log will probably be too slow to justify it over the P2P sync.
Docker commands
Docker commands that might be useful:
# see last 100 lines of logs
docker compose logs -f --tail 100
# stop and remove the container
# DO NOT force shut down hived
docker compose down
Witness node
To run as a witness you need to do additional steps. Generate a pair of keys and put the private key in your config.ini and add the public key to your hive account.
The secure option for generating keys would be something offline like the cli_wallet or some other wallet. But you could also use something like https://hivetasks.com/key-generator to generate random keys then copy one of the corresponding private and public keys. The website is safe at the time of writing. For this example I picked the generated posting key. It doesn't matter. You just need a pair of matching keys:
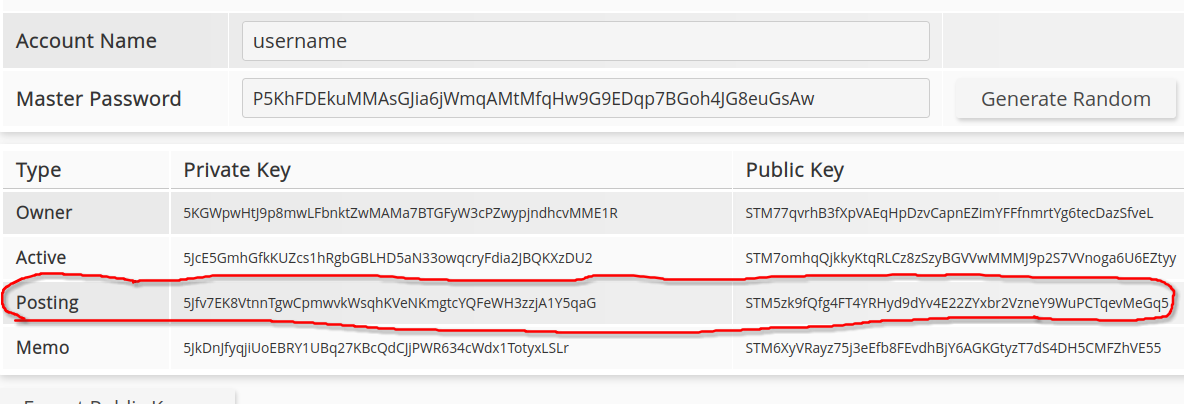{kind=link}
datadir/config.ini
witness="username"
private-key=5Jfv7EK8VtnnTgwCpmwvkWsqhKVeNKmgtcYQFeWH3zzjA1Y5qaG
Then you can use https://hive.ausbit.dev/witness to register a new witness or update an already existing one. You would need to login first to the website then refresh.
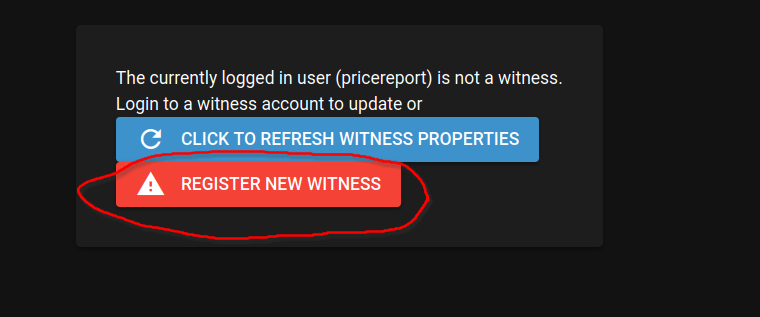{kind=link}
Then we put the public pair of our signing key in there and broadcast the the transaction:
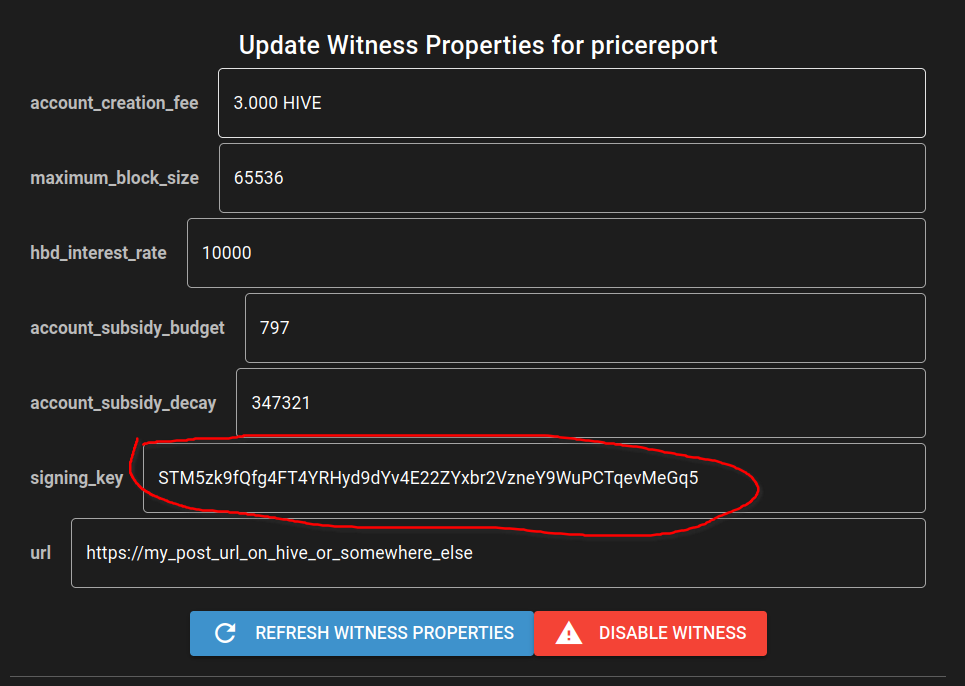{kind=link}
Scroll down and:
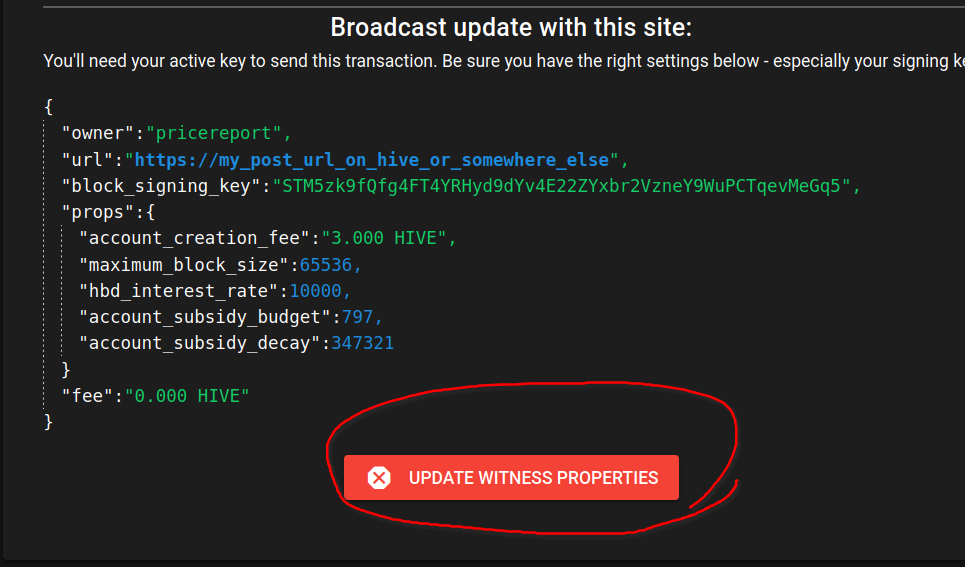{kind=link}
You can ask your technical questions in the official hive discord (which you can find on hive.io bottom of the page) or #witness or #dev channel on https://openhive.chat/
For future hived updates, you would just need to edit the hived version in the .env file and be good to go.
*The first image is taken from pixabay.com
{kind=link}
{kind=link}