HiveStats: Developer's Insight
[IMAGE: https://images.hive.blog/DQmUiVWhPMVaUd8SWaezvkTPMztFwcUNeXMfYz6KDSBcM3Q/image.png]
Introduction
As I do reply to some of the posts about HiveStats, you might already know that I'm the developer who is working on it, on behalf of LeoFinance. It might feel like I'm trying to steal their credit and trying to shout out to the whole universe about it; I do also feel a little like so, not going to lie. But, frankly, I'm rather a bit excited about it, that's all the reason. I was eager to do a project on Hive and working on HiveStats allowed me that even though it isn't my project. I'm excited because lots of people use it, and give feedback about it. I try to engage, fix bugs as quickly as possible to keep the illusion as if it is imperfect. So, in summary, this is the way I'm fighting my anxiety back.
I do love talking about programming concepts, I sometimes talk all day long. I did write up two posts about it last year, in the hopes of getting some engagement. While they got some votes from curation accounts, I got no reply, which discouraged me from writing any further posts. It could be because maybe my content wasn't up to the standards, or it was too abstract. Fast forward to 2022 and I now have the experience of developing an already existing app from scratch, which is less abstract and more practical, and popular, of course. So, allow me to share my shortcomings, struggles and solutions to those, so to call my experience, while developing HiveStats. I do apologize to all of you for my brashness for using this HiveStats popularity as an opportunity.
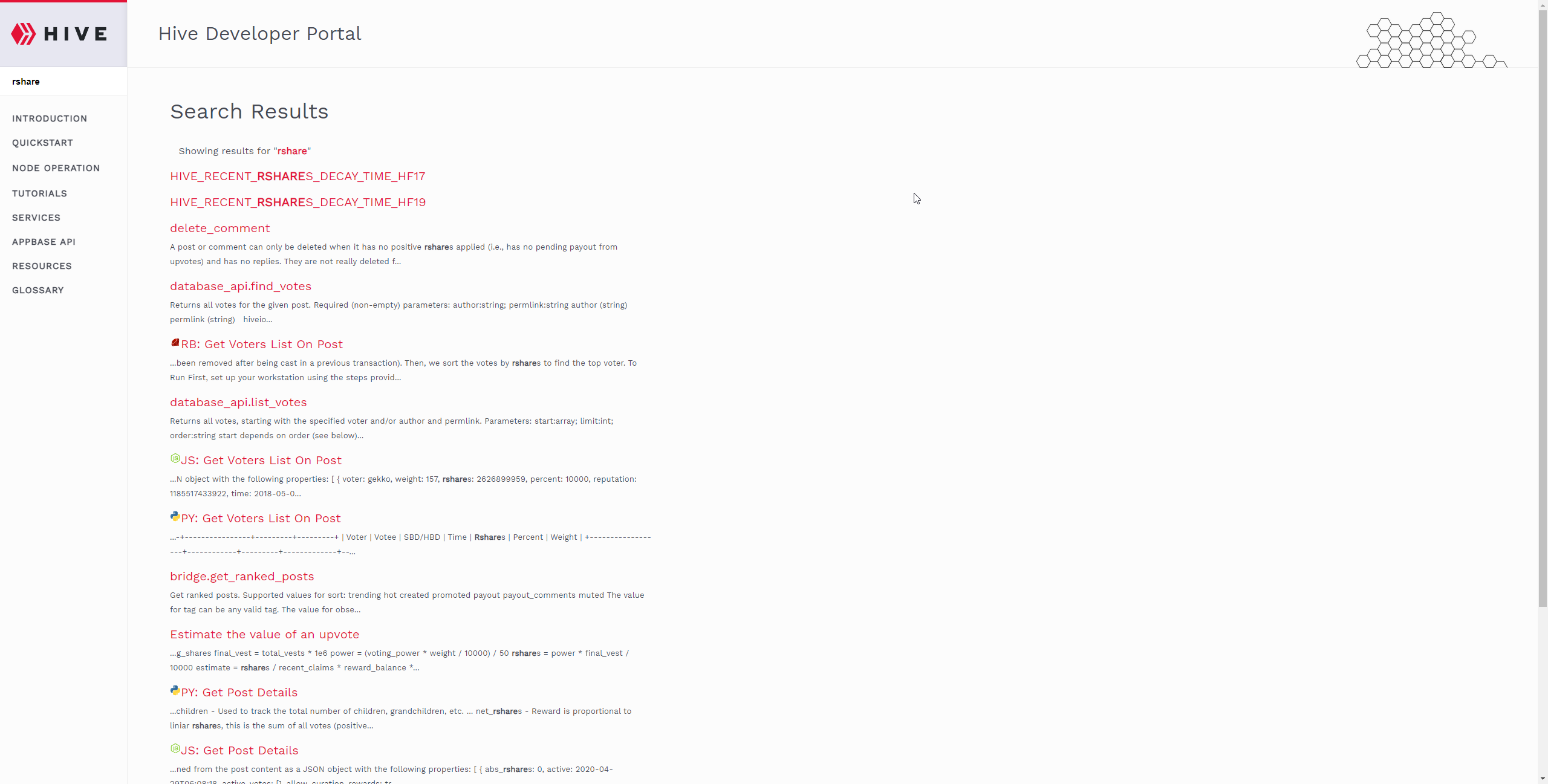
Lack of Documentation
[IMAGE: https://images.hive.blog/DQmb1evof3FCZwLRm76VhhBNyRiPQkG2McWC88R1cnzfyrq/image.png]
(searching what rshare means and its denominator)
I struggled with documentation the most, this was the most time-consuming issue by far. Documentation on Hive API methods was ok, but I can't say the same for the formulas and terms. To overcome it, I scraped example applications in the documentation, checked open-source projects that I know of, read lots of old discord messages. My Hive Engine experience was also similar.
I do plan to develop a handbook kind of website with search functionality due to this, to help other people like me.
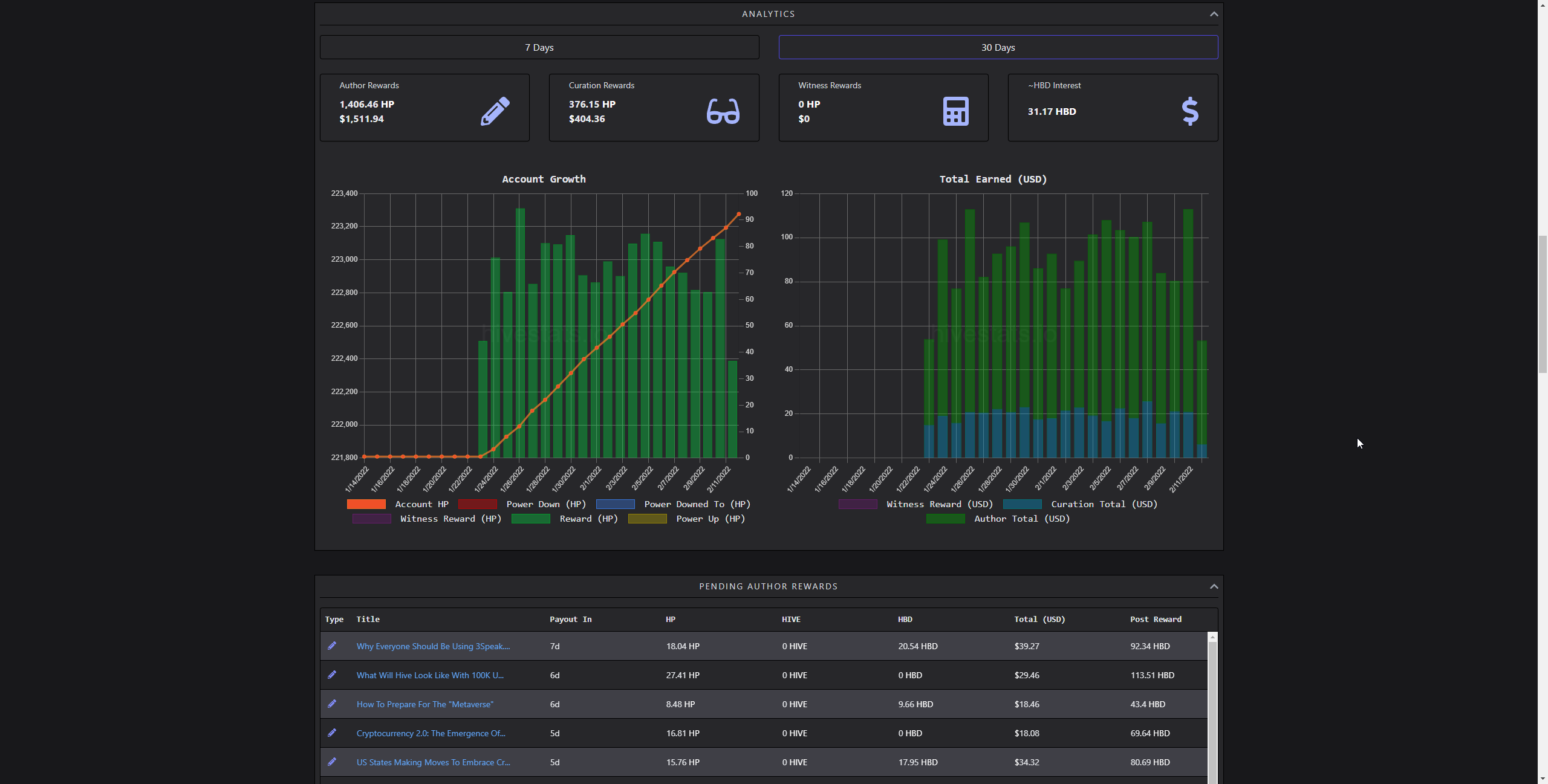
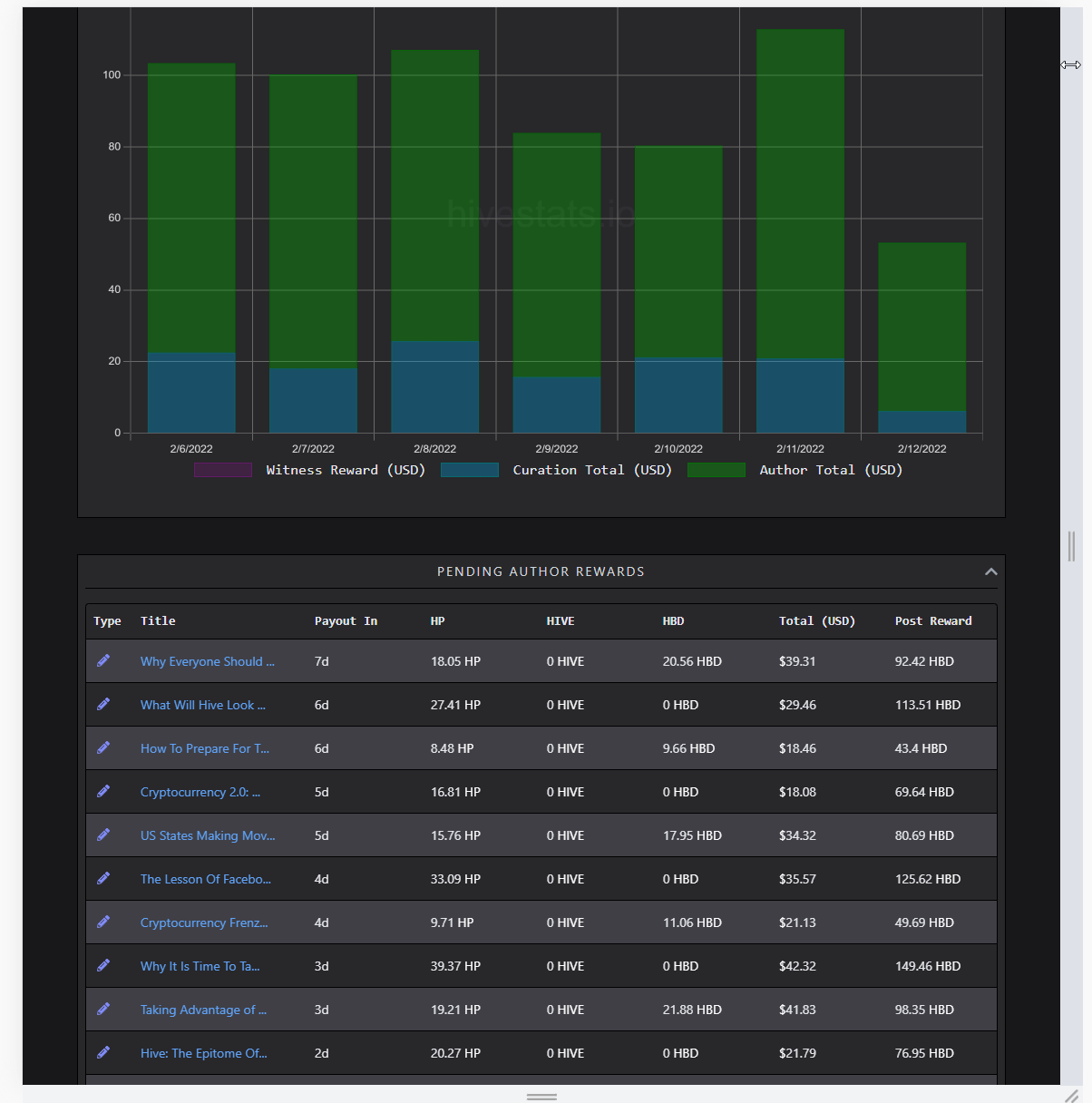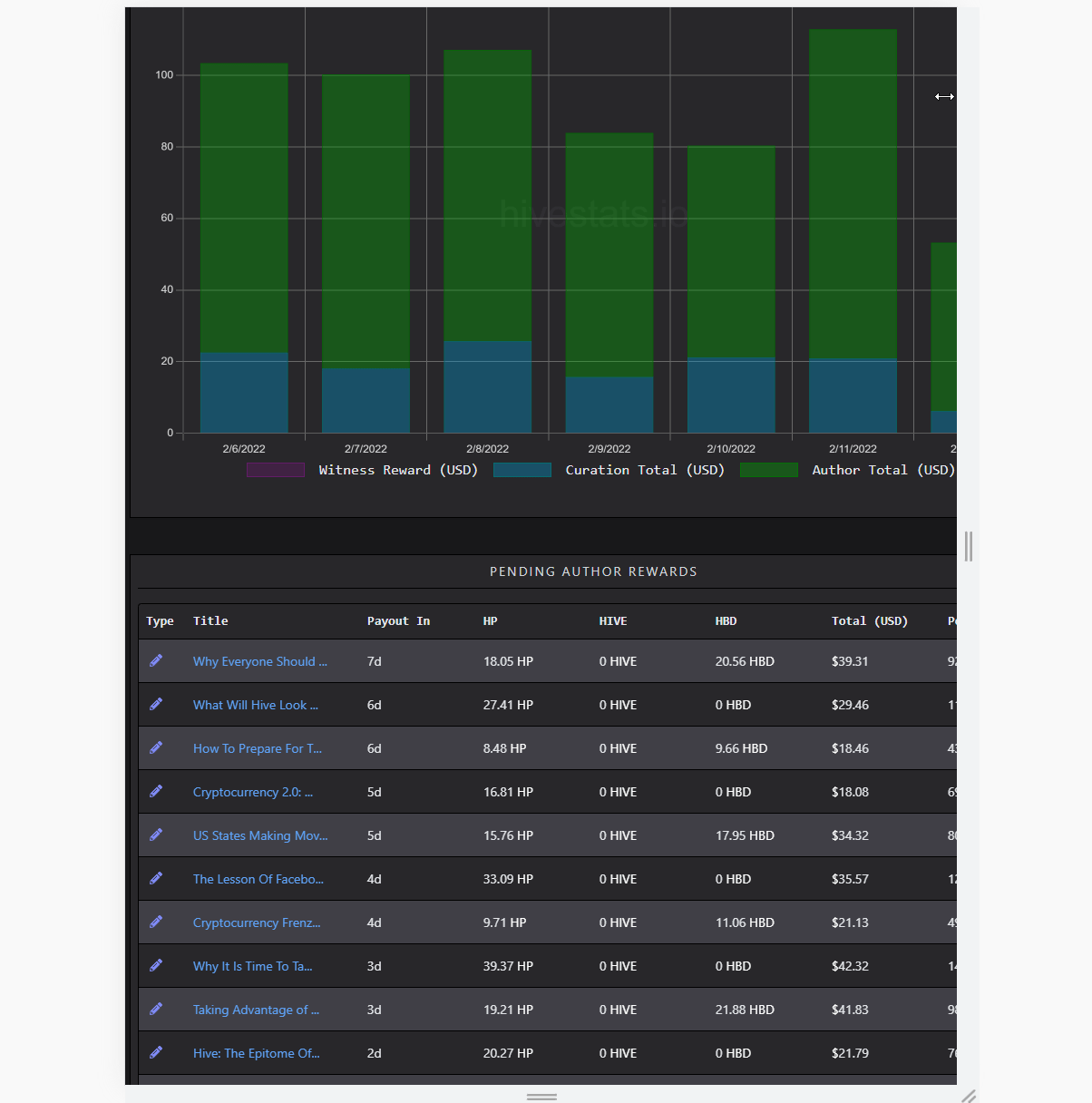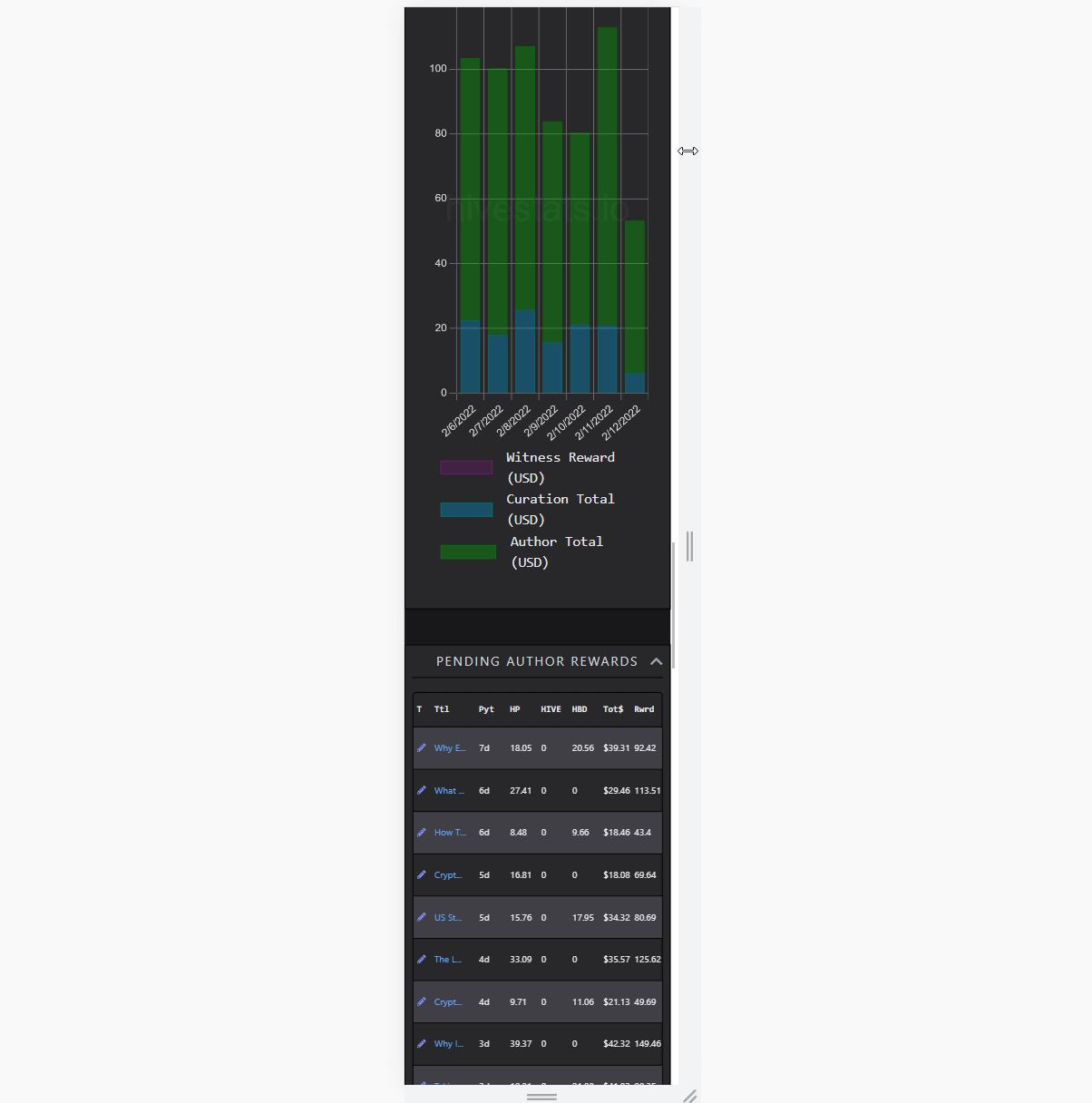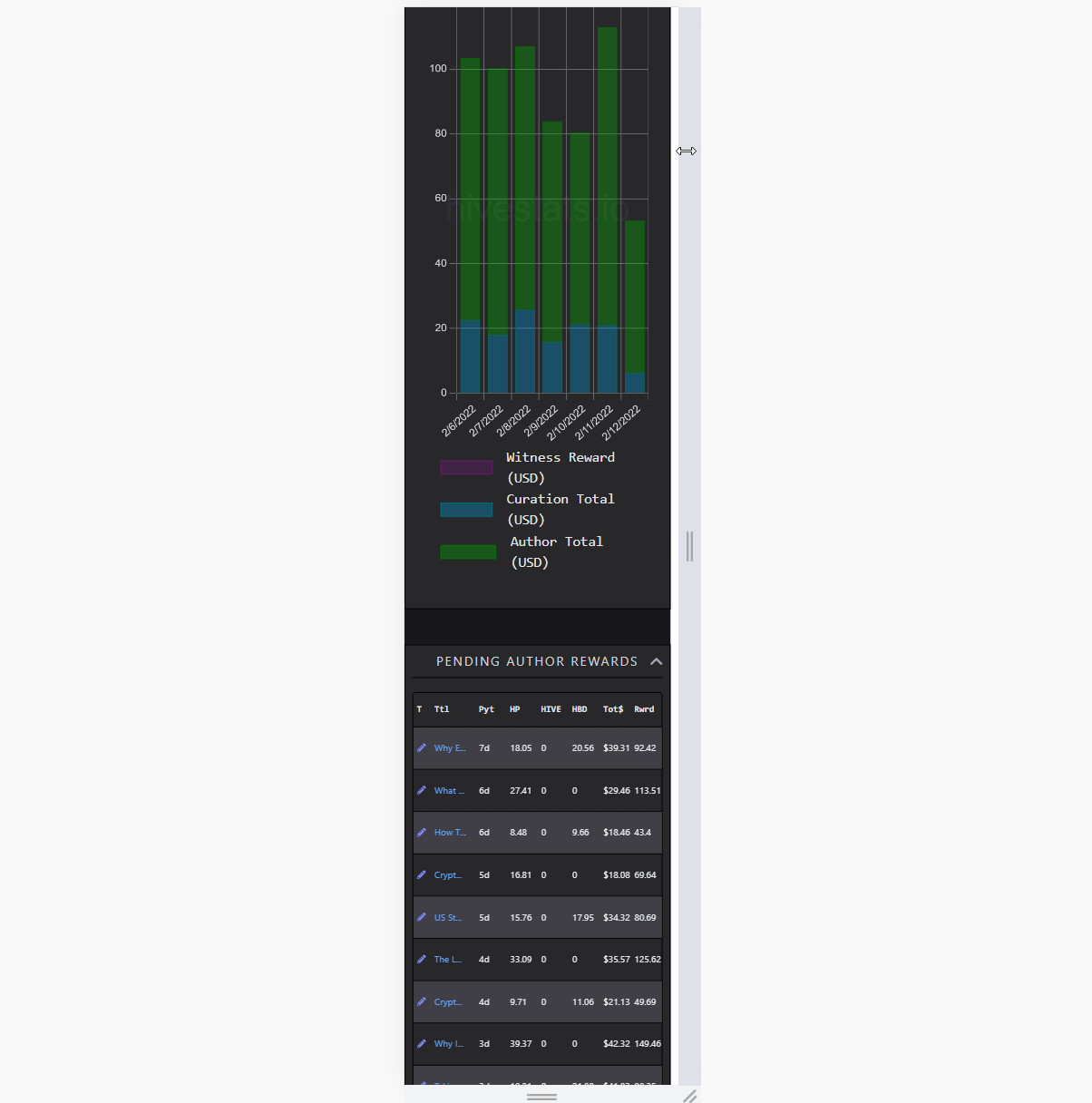
Account History
[IMAGE: https://images.hive.blog/DQmRJos517z5dJdH1tyUVvLDrcH1XFj36ZYUWEQRmFECq5d/image.png]
(showing partly loaded analytics)
Most of the stuff is calculated through parsing accounts' operations over time. For inactive account's like mine, it is just a simple call; but for people like @taskmaster4450, it gets dirty pretty quick. The thing is, reading the history is limited to 1000 items per request. There isn't a way of reading a week of history or month, so results of requests are read to figure out if it's past a month or not. Using that way, getting 50 history requests becomes sync as each request depends on another.
It was an issue of the old iteration of HiveStats, which I did solve in the V3 update. I did also improve upon it in the current iteration. The trick is making them partly async. Without boring details, I do predict how many requests it would take by using the first several requests. Later, I fetch them in batches. If they overshoot, I filter, if not, batch again. That way, it becomes several sync requests of async rather than all sync.
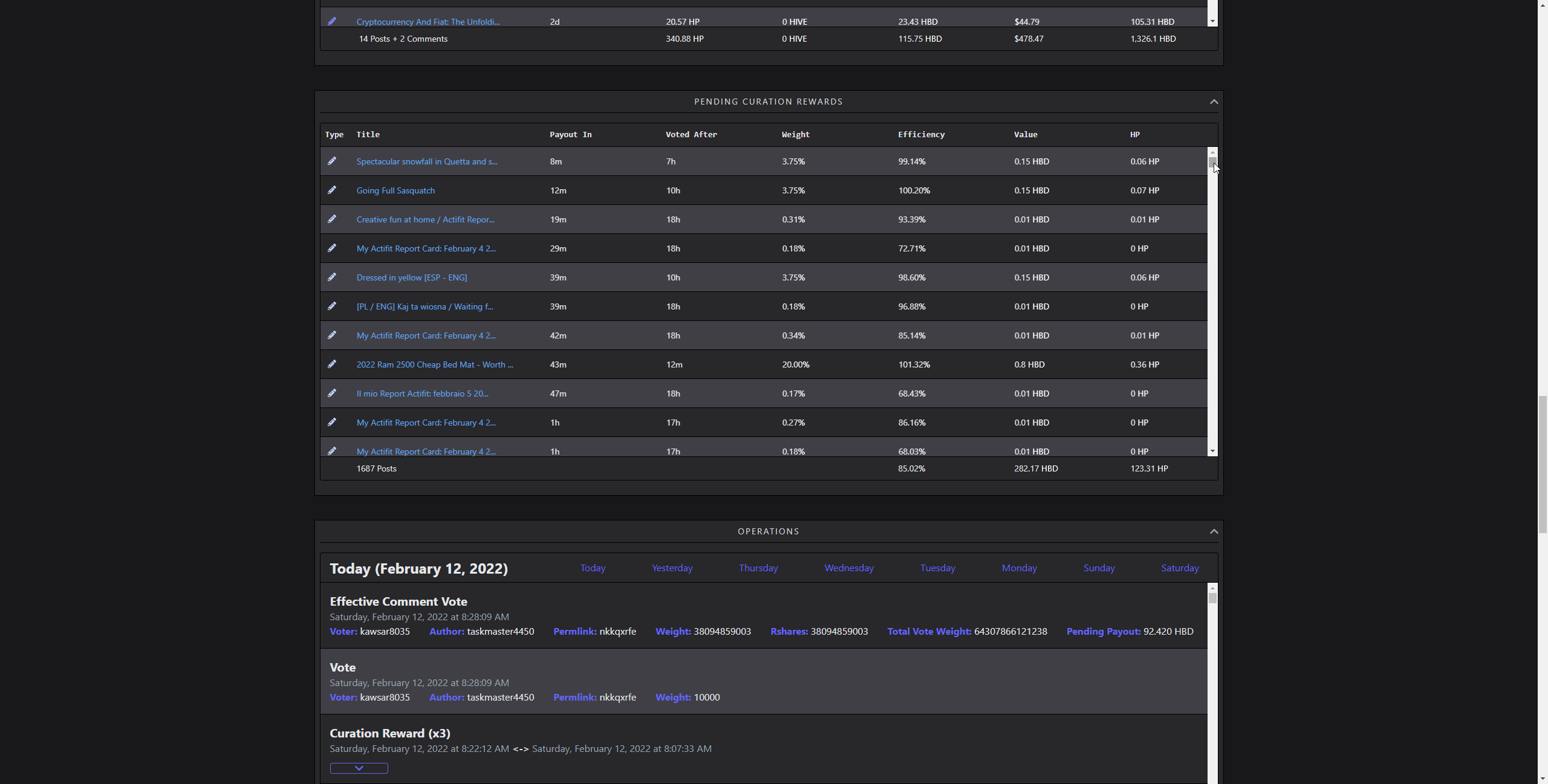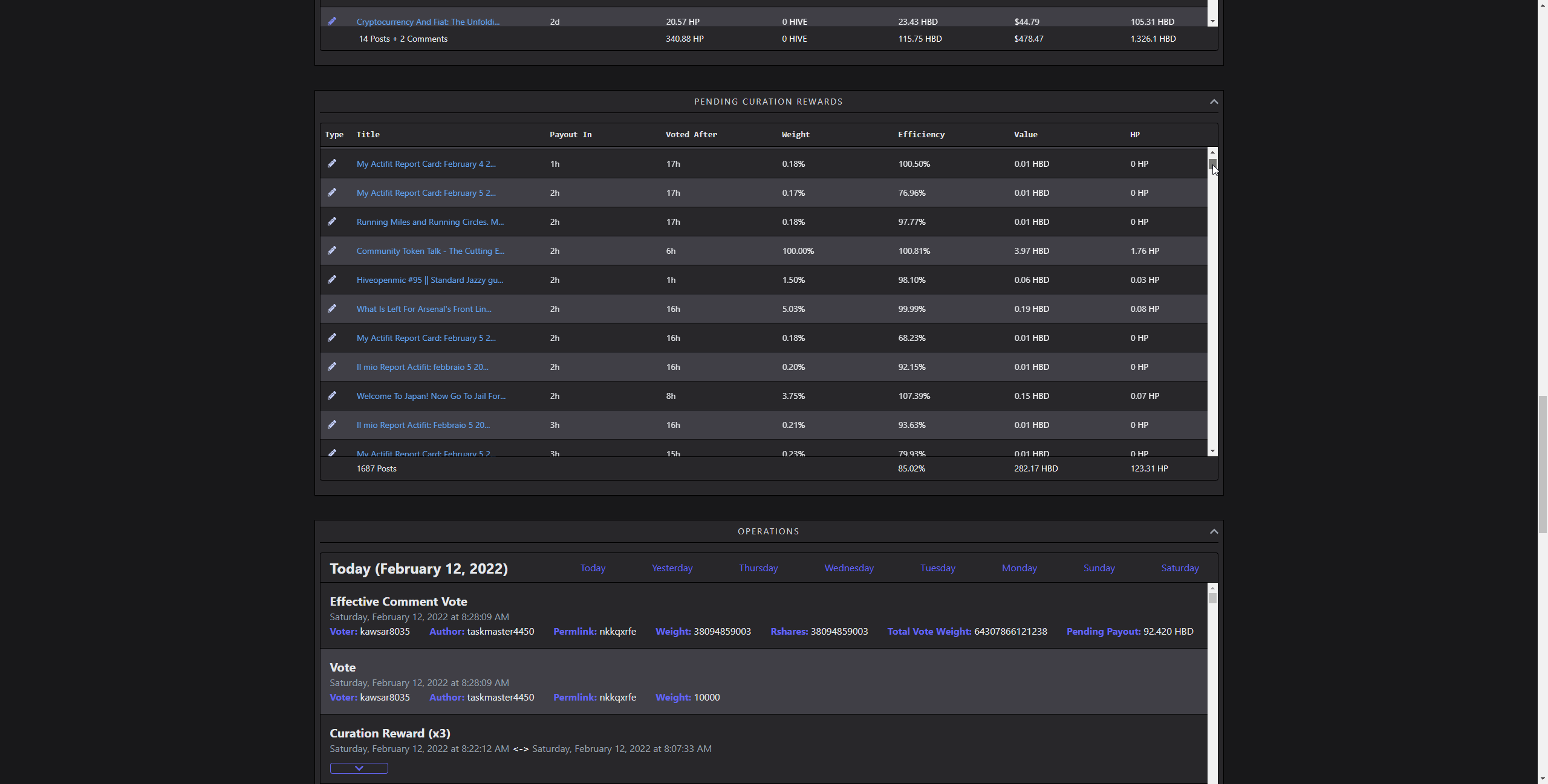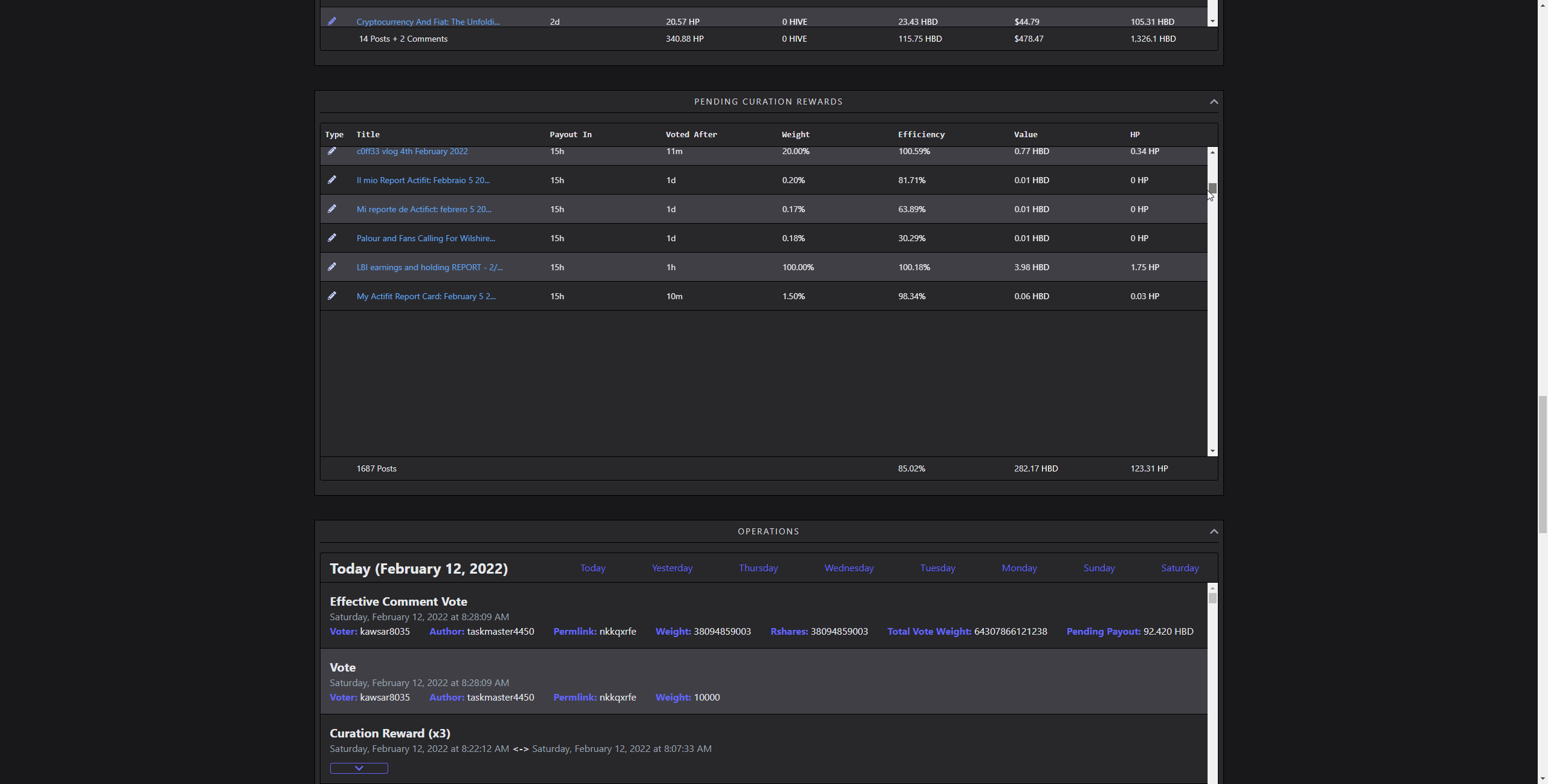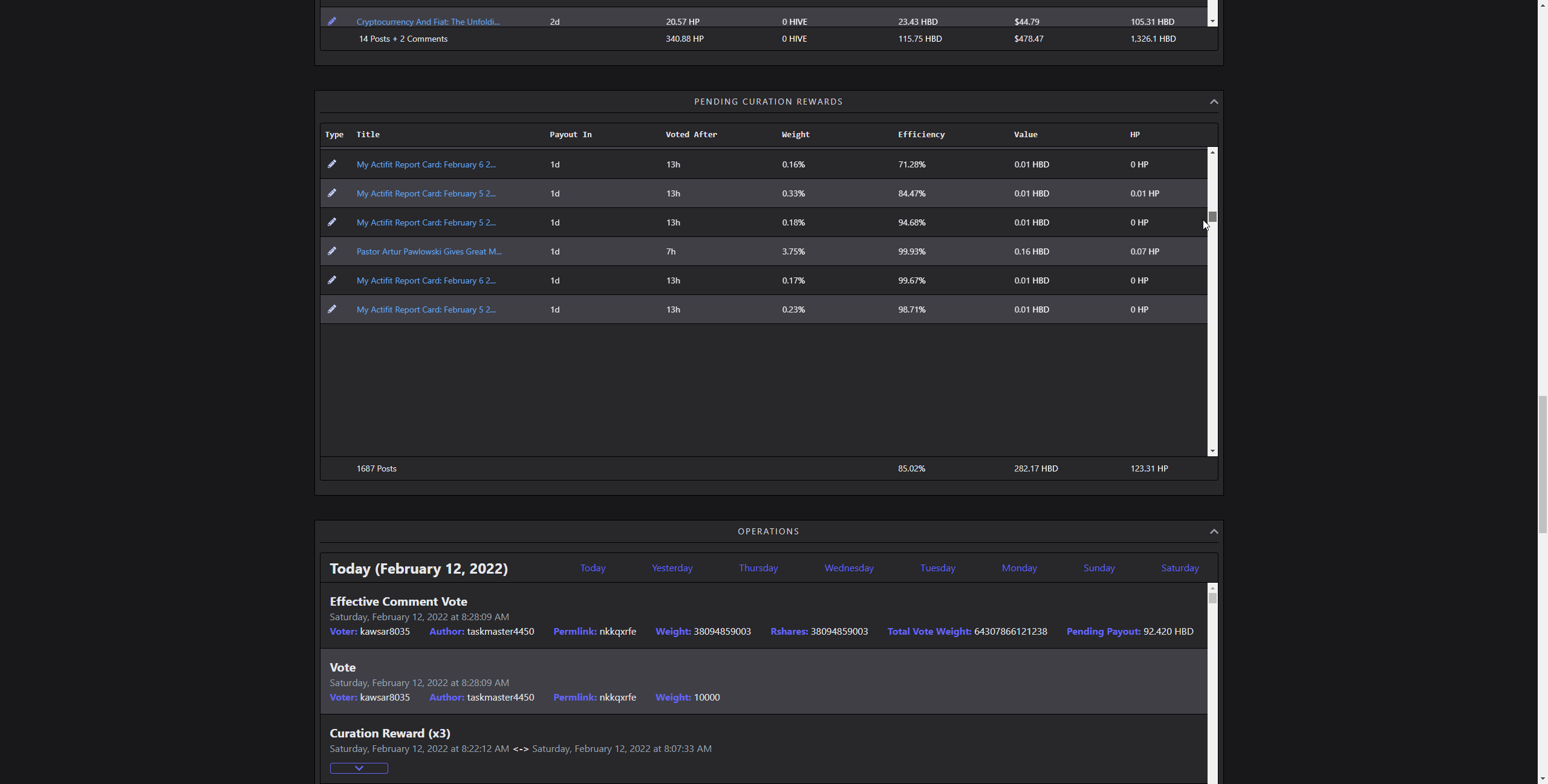
Curation Rewards and Operations
[IMAGE: https://images.hive.blog/DQmcSNtQ13gJTeD9Dez5YHwco28dPceD82YQ9iiLyoNgjuh/chrome_2022-02-12_08-31-05.gif]
(scrolling through 1657 rows)
Visualizing lots of data without combining them into something, like a chart is demanding. Rendering several thousands of complex elements as rows of a table takes time. Updating it on the go several hundred times makes the framerate unstable. It doesn't matter how fast it is fetched or parsed, if it feels sluggish, that's a bad UX. I did solve this by using a technique called windowing. So, rendering only the parts user is currently seeing, and reusing old elements in the process. While doing that, simulating scroll behaviour and memoizing heavy renders is also crucial. That way, it creates an illusion of lots of items, in reality, showing only a dozen of them.
Mobile Support
[IMAGE: https://images.hive.blog/DQmWQYvDZ1dq3unw3s9f8mv4u5GTMgVjiLWUR9wmS7z4b61/chrome_2022-02-12_08-34-11.gif]
(simulating narrower screen view)
Mobile support is hard, making tables mobile friendly is harder. I struggle a lot to fit every bit of information on the tables, without horizontal scrolling. I did reduce the font size, used abbreviations, cut most of the title on lower screens to fit everything. While the execution was easy, it took lots of time to test and figure perfect values.
Making it Feel Reactive
[IMAGE: https://images.hive.blog/DQmYKLSmC1yRgREz7Gkkgv76qGQToNCrMwd2QGQwyZX5imq/chrome_2022-02-12_08-36-17.gif]
(fetching post data while updating the table)
As I said in a previous paragraph, if a UI feels sluggish, that's a bad UX. In the frontend world, the most important thing is controlling how a user feels. Websites with more features might get lower traffic due to how they act to the user's actions and vice-versa. For HiveStats, unlike other sites, loading an account is the most important action of the user, so making it reactive was necessary. The difference between V3 and V4 is not much in terms of raw speed, but as the latter feels more reactive and updates constantly, it makes the user focus on updated data rather than waiting for it. That way, it cheats badly, creates the illusion of being far faster. That's the power of UX. React's one-way data flow and using memoization was crucial in this process.
Important Techs/Libraries I Used
- TypeScript
- React
- TailwindCSS
- React Router
- React Virtuoso
- DHive
- Formik + Yup
- Immer
- date-fns
- nginx
- Docker
So, hope you like it. I tried to not be boring while providing enough data and making it a quick read. If you have any questions, I am happy to reply to all of them. See you later, thanks for tuning in!
Posted Using LeoFinance Beta
@klevn | Feb. 15, 2022, 11:47 p.m. | Votes: 0 | [
VOTE ]
i have not been on discord. let me set a level of understanding. hopefully you can decode this.
I have gotten the majority of the values below. I have not found what the 'weight' is .. it is not actually found on this page, however is used in the formula.
total_vests = vesting_shares + received_vesting_shares - delegated_vesting_shares
final_vest = total_vests * 1e6
power = (voting_power * weight / 10000) / 50
rshares = power * final_vest / 10000
estimate = rshares / recent_claims * reward_balance * hbd_median_price
I found this and tried to follow and find the values it used...
curation reward estimation tool appears to be helpful..
The Details
For those of you who are interested, the calculations work as follows:
let [before] = the value of votes before the specified account voted
let [vote] = the value of the specified account's vote
let [total] = the total payout value of the post (as specified using the slider bar)
let [reverse_auction_%] = the portion of your curation rewards that will go to the author if you voted before the post was 30 minutes old
Each of the above amounts is multiplied by 25% since that is the amount of rewards that go to curation. Then the curation value can be calculated by:
(√([before] + [vote]) - √([before])) * √([total]) * (1 - [reverse_auction_%])
i have not found reverse_auction_% yet.
my understanding is, I need to total the value of all the votes on the post.. as the post total value affects how much you get depending upon when you voted.
so estimating it implies guessing how much the post value would be, or leaving it as is and estimating it as if it received no more upvotes (which is what I planned to do, not actually ignoring the other option just not having thought about how to do it yet)
this is result from my code, with a effective_comment_vote that I think holds the part of the key
op = effective_comment_vote {voter klevn author leny28 permlink flor-aspilia-africana-african-aspilia-flower weight 54948050199 rshares 54948050199 total_vote_weight 110142200252 pending_payout {0.148 HBD}}
and here are the values I've pulled that I thought would be used to calculate this
voteValues>>
reward_balance:755637.683
recentClaims:600562913345957605
base:1.049
>>
accountInfo>>[klevn]
vesting_shares:3109480.378777
received_vesting_shares:3109480.378777
delegated_vesting_shares:0.000000
voting_power'current:97.75
it appears to me the best I could do it search on the post for the most recent upvote
from there I pull the pending_payout {0.148 HBD}} (which will have changed.. i think) along with the other values there.. are used to calculate it.
thanks for any/all help. appreciated so much . I hope I have been clear. I am working to wrap my mind around the concepts used.
a side note (in regards to documentation not being good) .. but this threw me for a loop..
condenser_api.get_account_history
"alice" -1 1000 Queries the account named alice starting on the oldest item in history, up to 1,000 results.
it says oldest item in history. it is actually the newest item in history. because I was so new I thought I must be thinking wrong, but no .. well maybe you can explain it. but i think it is wrong.
> I have gotten the majority of the values below. I have not found what the 'weight' is .. it is not actually found on this page, however is used in the formula.
This one is estimated upvote/vote value calculation. Weight is voting mana ratio (out of 10000, not percentage), so it calculates user's vote value rather than post's. Hope it is clear! Don't hesitate to ask further if not.
> i have not found reverse_auction_% yet.
It is probably an old way of calculating it, I don't know about it.
> my understanding is, I need to total the value of all the votes on the post.. as the post total value affects how much you get depending upon when you voted.
so estimating it implies guessing how much the post value would be
Exactly!
Rest about curation is not correct, I'll provide the details.
> it says oldest item in history. it is actually the newest item in history.
I did also struggle with several wording there, one of was that. What it means is, data it returns is sorted oldest to newest. So, imagine getting last 50 history of an account. The array it returns is sorted from the oldest, so if the latest operation was with index 24424, that would be the last index of the array. So, it is reverse than what you expect. This isn't true for HiveEngine for example, if you ever go into that route!
Now, about curation rewards. I'll provide examples as pseudocode:
You'll need these methods and fields:
- get_current_median_history_price -> base // median price of Hive/HBD
- get_reward_fund-> percent_curation_reward // curation reward ratio (50/50 as of now)
- get_content -> pending_payout_value, max_accepted_payout, total_vote_weight, active_votes
You do need to calculate post rewards first:
function post_reward(median_price, pending_payout_value, max_accepted_payout) {
// We do only use max allowed value (read about min function if this looks nonsense)
// I don't know where max_accepted_payout is used, it could be declined rewards.
let payout = min(pending_payout_value, max_accepted_payout);
// We do convert Hive to HBD as pending_payout_value is Hive.
return payout / median_price;
}
Next, you need to calculate how much of this is curation reward:
function curation_reward(post_reward, percent_curation_rewards) {
// percent_curation_rewards is a ratio. I'm not native and don't know
// how I can describe it, but it is like 24/100, but scaled up to 10000
// so like 2400/10000. percent_curation_rewards is the 2400 part of it
// They do use 10k instead of normalized value, probably for precision reasons.
if (post_reward == 0) {
// If we don't this, it could return NaN in rare cases.
return 0;
}
// 1000 is denominator here, used for precision calc.
let hive = post_reward * 1000;
// we do multiply high precision high value by percent, later floor it to cut out
// possible unnecessary precision bits. later divide it by 10000. I described
// reason at top.
let curation_reward = floor(hive * percent_curation_rewards) / 10000;
// As we don't need to make calculations over this, we can divide it back.
return curation_reward / 1000;
}
Now, we can calculate the vote reward:
function vote_reward(curation_reward, total_vote_weight, weight) {
// Self explanatory I believe
let ratio = curation_reward * 1000 * weight / total_vote_weight;
// Making sure negative values result in 0 (due to downvotes). Then floor and denom
// as like above.
return floor(max(0, ratio) / 1000);
}
Ta da, now you have curation reward as Hive/HP. You can combine these into one function and reduce the amount of denom operations you do. So it could be like this:
function curation_reward(
median_price,
pending_payout_value,
max_accepted_payout
percent_curation_rewards,
total_vote_weight
weight
) {
let payout = min(pending_payout_value, max_accepted_payout);
let post_reward = payout / median_price;
if (post_reward == 0) {
return 0;
}
let hive = post_reward * 1000;
let curation_reward = floor(hive * percent_curation_rewards) / 10000;
let ratio = curation_reward * weight / total_vote_weight;
return floor(max(0, ratio) / 1000);
}
I didn't show how weight is calculated, about that: Well, you can find it by filtering active_votes. It has a limitation though, active_votes don't show more than 1000 votes. I didn't solve it in HiveStats as it is quite rare. But I do believe that a workaround should be possible, like calculating weight by yourself using shares or using another method like: https://developers.hive.io/apidefinitions/#database_api.list_votes
@klevn | Feb. 16, 2022, 11:48 a.m. | Votes: 0 | [
VOTE ]
Thank you! So wonderful!
The following, is one issue. and a question about that. and reason why I care about it.
>I did also struggle with several wording there, one of was that. What it means is, data it returns is sorted oldest to newest. So, imagine getting last 50 history of an account. The array it returns is sorted from the oldest, so if the latest operation was with index 24424, that would be the last index of the array. So, it is reverse than what you expect. This isn't true for HiveEngine for example, if you ever go into that route!
I understand this, the array is reversed, what is not clear is there is no other way to get to the newest item.. there is no way to have it ordered newest first..
so as you read thru it .. very unclear how to achieve this .. and given your struggle as well.. is there someone who we can bring this up with? because I actually find it super annoying to have things so unclear.
I have just stepped away from linux because I found it 'less than' open source in its actual implementation. so here I am curious the level of feedback we could get on such an issue. on linux they care not what the users think and projects, like gnome, often corporate entities.. and have just become bad if you ask a search engine .. this bit made me laugh from a comment..
>- Gnome really looks like it has been designed for and tested against mentally challenged people. It's infuriating, most of its utilities lack menus and basic options/settings, to the point where having a GUI is more of an impediment rathen than being something useful.
>I am very worried by the fact that Ubuntu is reverting back to Gnome.
source
this is what happens if we don't mind our source !
can we help make such improvements? are there ways to get in touch that you are aware of ? i feel like discord is the way.. but I haven't really seen any obvious 'avenue' inviting me there .. or i just missed it. (aside from you, of course)
it will take me a moment to digest the code . thanks for taking the time. wanted to push that out of my thoughts before I continued to think on this.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}